Nakupovalnik: a home-brew webshop crawler
Nakupovalnik was in development 2006-2007 and put out of its misery in 2012.
Intro
One of the first coding projects that wouldn’t let me sleep for prolonged periods of time. It started out as a web crawler, written in Perl, that became impossible to maintain and was hence rewritten in Ruby. Why Perl in the first place? Because of the magical feeling I got when I wrote my first Perl script; being a seasoned VB6 programmer since 1990s I found Perl with its regexes and string processing facilities unbelievable. But the ugliness of its function calls led to all of the crawler being contained in just one immense loop, branched into dozens of ifs. Unmaintainable is an understatement; not only could I not maintain it, I couldn’t even understand it any more. The rewrite was much more concise, and Ruby was (and still is) remarkably Perl-like.
The entire project took me through the common repertoire of crawling topics, from URL normalization, to URL revisitation policies, and in the process:
- filled the entire disk (a MySQL database) with copies of basically the same URL, differing only in random variables like PHPSESSID
- got my IP banned from multiple online stores
- consumed an entire summer’s worth of free time.
The crawler
The initial idea was relatively simple, and the practice was novel enough and not described (or discouraged) well enough on Wikipedia: just start with the URL of a single web store, fetch the page, extract links, add links to database, and repeat, over and over. This led to multiple #FAILs and subsequent adjustments, among them:
- limiting the crawl to a single domain, or it would run wild
- parse URLS from fetched pages, but don’t forget to expand relative paths to absoute paths
- ignore random GET parameters, such as phpsessid, cftoken, etc.
- order get parameters alphabetically to avoid crawling same resource multiple times
- don’t fetch images, styles, javascripts, PDFs, etc.
- don’t store resources with content type other than text/html
- finally: allow whitelisting and blacklisting general url patterns to speed up the addition of new web properties.
Crawler was only the first part, however. All pages deemed worthy (product pages, identified either by an url pattern or a DOM + regex match) were saved to a database. To save space, gzip was used to compress each body.
I developed multiple optimizations to handle specific cases; for example, the largest store around had Sitemaps, which I discovered accidentally, but a specialized sitemap_crawler saved me a bunch of traffic and updates by only fetching the changed pages. Similarly, small stores could sometimes be tricked to display all the products in one search results page by issuing an empty query and fixing the url to display 1000000 hits.
Still, many sites banned me for agressive crawling, and I tried hard to keep track of the the bandwidth consumed to estimate when I should give a site some break. Bandwidth was not cheap back then.
Just for taste, here’s a snippet of the Ruby code which was much more pleasant to my eyes than equivalent Perl code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def RebuildUrl(url)
if url !~ /\?/
return url
else
addr,params = url.split("?")
return addr + "?" + params.split('&').sort.join('&')
end
end
def removeImageURLs(links)
@cleanLinks=Array.new
links.each do |link|
if link !~ /.*\.(png|jpg|gif|css|ico|js|swf|pdf|doc|avi|mpg|mp4|mp3|wav|mid).*/i
@cleanLinks.push(link)
end
end
return @cleanLinks
end
def stripSessionFromURL(links)
@newLinks=Array.new
links.each do |link|
@newLinks.push(link.gsub(/(phpsessid|mscssid|cfid|cftoken|jsessionid)=([^&]*)&?/i,""))
end
return @newLinks
end
The parser
Then, another process took over the content, running in parallel to the crawler. It took one page at a time, uncompressed it, tried to guess its encoding based on the presence of certain characters, and extracted the names, descriptions, image links, urls and prices from the body. To do that, it used a two-step process:
navigated to a product using a manually entered XPATH (at that time, excellent library Hpricot was used to do that) and extracted the final data field using a regex Finally, it saved the parsed fields to a database.
Later, image fetching was also added to generate thumbnails for the search.
Here are some screenshots of the web GUI I made to manage the entire distributed operation.
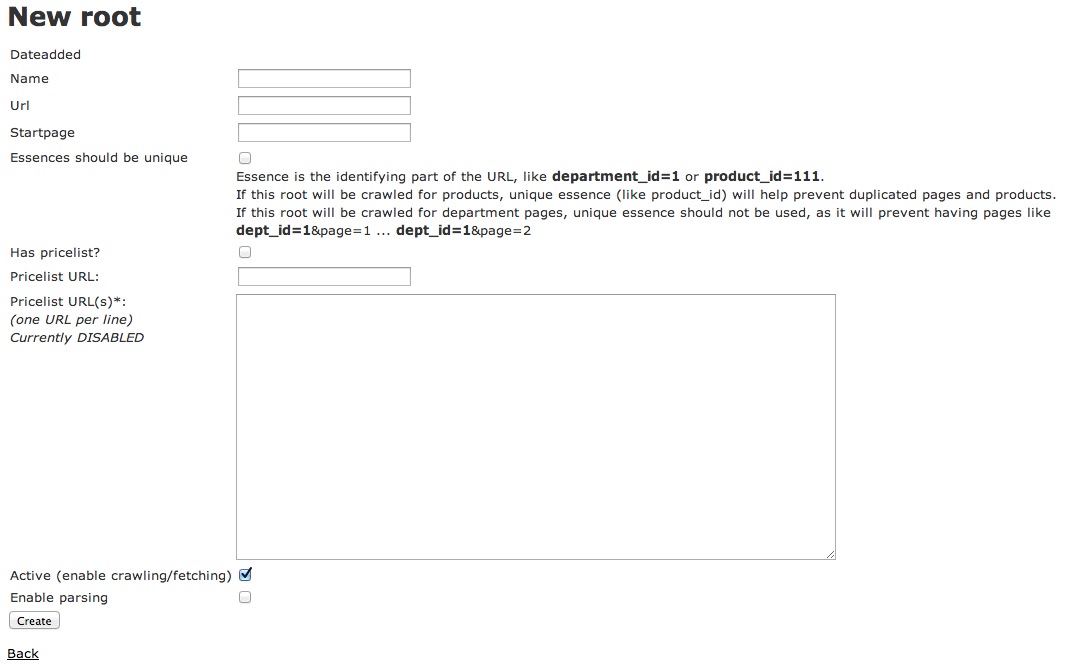
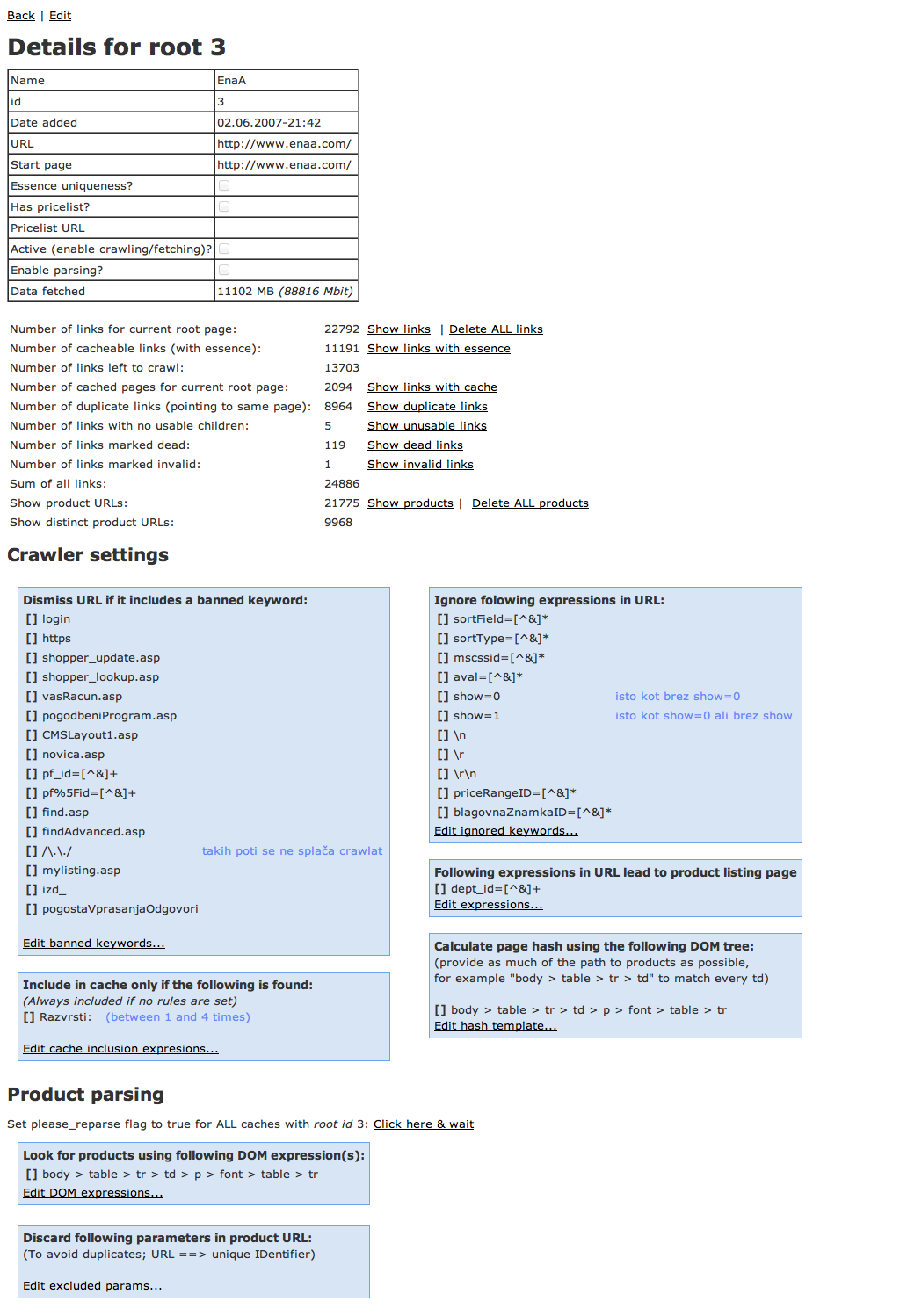
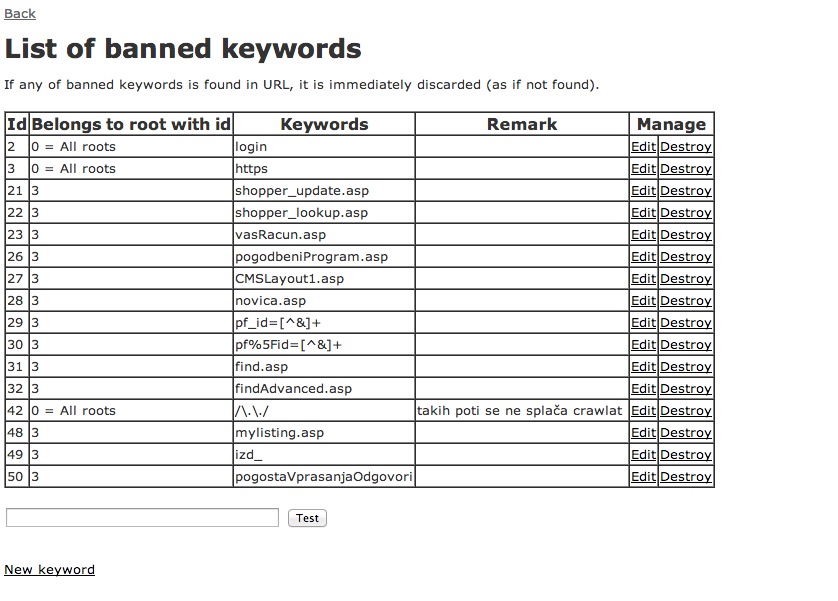

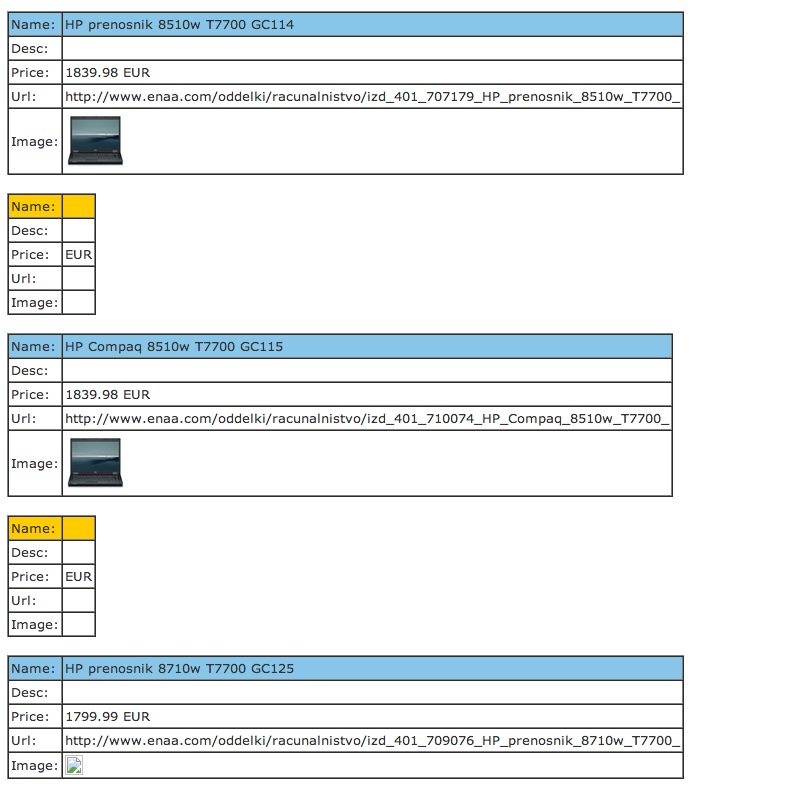
The search engine
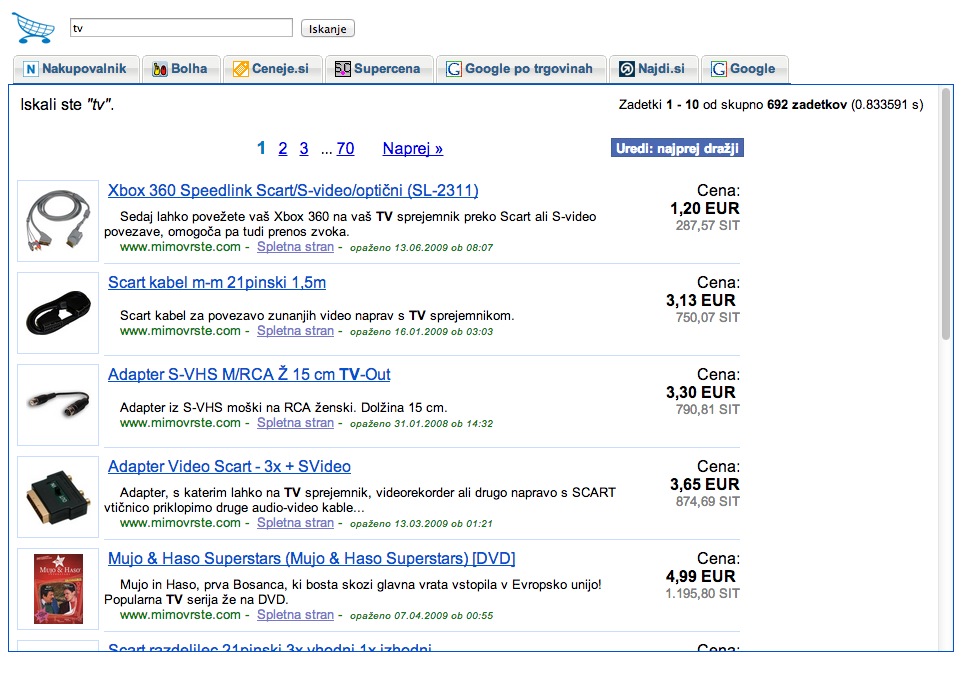
And the final stage was the search engine, querying mysql using full-text index to find the products; this was the first time I had to dive deep into indices, query optimization and tweaking MySQL to reduce the query time from dozens of seconds to mere seconds.
Logo, of course, was designed by me back, in the day when I thought I can do it all by myself.
And in the pics below, you can also see my first pivot; competition was fierce in the field of comparison shopping: Google had its product search, and in our local market, two competitors sprung up at the same time as I was attempting my solo experiment driven entirely by curiosity. I decided to integrate them all into an iframe with a tabbed view. Good times.